2024/4/8 北米皆既日食を見てきました
概要
2024/4/8にメキシコのクアトロシネガスで皆既日食を見てきました。皆既日食は2017年にアメリカで見て以来生涯で2度目でした。今回は天気予報が1週間前からずっと悪く、当日も曇りでしたが、薄雲越しにほぼ全過程が見えるというミラクルな展開でした。皆既日食は何度見ても感動しますね。行ってよかったです。
薄雲の向こう側でばっちり皆既日食を捉えました。どうしても雲の影響はありますが、コロナの細かい構造まで撮影できてよかったです。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/1000s~1/2s まで1EV刻みで10枚の画像をステライメージ9でスタックし回転アンシャープマスク, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/1000s~1/2s まで1EV刻みで10枚の画像をステライメージ9でスタックし回転アンシャープマスク, PhotoShop, DenoiseAI
上の写真は回転アンシャープマスクを2回かけて強調しましたが、こちらは1回だけにして眼視のイメージに近づけてみました。眼視だとプロミネンスがもっと赤く見えるのですが、なかなか写真では表現しづらいですね。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/1000s~1/2s まで1EV刻みで10枚の画像をステライメージ9でスタックし回転アンシャープマスク, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/1000s~1/2s まで1EV刻みで10枚の画像をステライメージ9でスタックし回転アンシャープマスク, PhotoShop, DenoiseAI
第2接触直前のダイヤモンドリングです。薄雲越しなのでちょっとソフトな感じですが、むしろ幻想的な感じになってこれはこれでアリだと思います。薄雲越しだからかゴーストがほぼ出ておらず、綺麗に撮影できたと思います。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/500s, ステライメージ9, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/500s, ステライメージ9, PhotoShop, DenoiseAI
第2接触時のプロミネンスです。これも薄雲越しですが、はっきりと写すことができました。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/250s, ステライメージ9, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/250s, ステライメージ9, PhotoShop, DenoiseAI
第3接触直前のダイヤモンドリングです。これは動画からの切り出しです。プロミネンスの側から光が現れてとても美しかったです。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/60s, 動画から切り出し, ステライメージ9, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/60s, 動画から切り出し, ステライメージ9, PhotoShop, DenoiseAI
第3接触直前のプロミネンスです。右下に出ているプロミネンスが今回見えた中では最大でした。
 撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/60s, 動画から切り出し, ステライメージ9, PhotoShop, DenoiseAI
撮影データ: BORG 107FL, 7108フラットナー, SONY α7S, 648mm, f/6.1, ISO100, 1/60s, 動画から切り出し, ステライメージ9, PhotoShop, DenoiseAI
皆既日食時に広角で撮影していた動画から切り出した画像です。金星と木星は余裕で写っているのでかなり薄い雲だったのだろうと思います。
 撮影データ: Tamron 20-40mm, SONY α7C, 20mm, f/2.8, ISO100, 1/60s, 動画から切り出し, ステライメージ9
撮影データ: Tamron 20-40mm, SONY α7C, 20mm, f/2.8, ISO100, 1/60s, 動画から切り出し, ステライメージ9
2017年のときの記事はこちらです。このときは雲一つない快晴でこれ以上ない成功でした。今回は快晴とはいきませんでしたが、事前の天気予報からすると大成功と言っていいと思います。
検討
2017年にアメリカで皆既日食を初めて見たのですが、2024年にも北米で皆既日食があることはわかっていたので、そのときから計画は始まっていたと言えます。皆既日食を見ると、また見たくなることを、俗に日食病と言うらしいのですが、私は完全に日食病に感染してしまったようです。
2023/10ごろに具体的に今回の旅の検討を始めたのですが、検討ポイントは3つほどありました。
どこで見るのか
今回の皆既日食は、ダラスなど日本からアクセスしやすいメジャーな都市でも見られることがわかっていたので、当初はアメリカで見ようと思っていました。しかし、気候を調べていると、4月のアメリカ東部~南部はかなり晴天率が低いことがわかってきました。せっかく行っても、天候が悪いと皆既日食を見ることはできません。今回の皆既日食はメキシコ~アメリカを通過するのですが、晴天率についてはメキシコの方が高く、観測の成功率を高めるにはメキシコの方が良さそうに思えました。
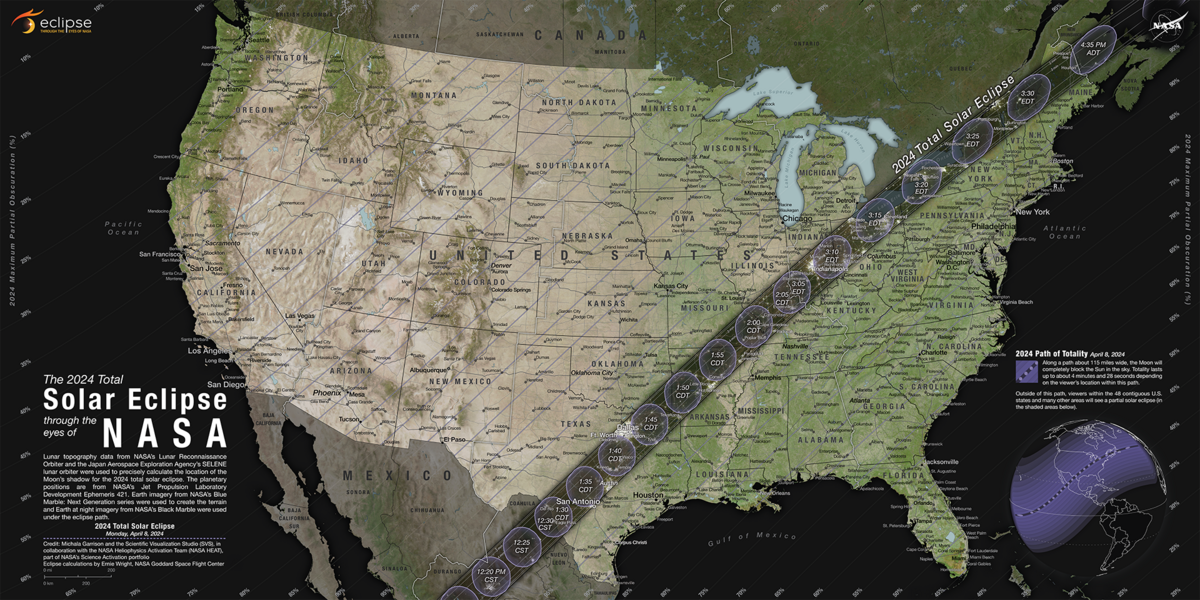
https://science.nasa.gov/eclipses/future-eclipses/eclipse-2024/where-when/
子供を連れて行くかどうか
私には小学生と保育園児の子供がいます。保育園児の方はさすがに皆既日食を理解できないですが、小学生の方は理科が好きで皆既日食にも興味を示していました。小学生ともなれば、一生の思い出になるだろうと考え、連れて行きたいと思いました。4月の上旬なので、旅程の半分くらいは春休みで、1学期の始業式から数日休むことにはなりますが、大きな影響はないだろうと判断しました。 なお、私も当然ながら仕事を休む必要があります。私はただのサラリーマンなので、4月に1週間休むのは多少抵抗がありましたが、私は社畜失格なので堂々と有給休暇を行使することにしました。ここは快く送り出してくれた同僚に感謝です。
旅行の手配をどうするのか
メキシコへ行くとなると、言語の壁や治安の面で、アメリカに行くのとは難易度がだいぶ変わります。2017年のアメリカでは個人で飛行機とレンタカーを手配して適当になんとかなったのですが、メキシコでしかも子連れとなると安全を確保する自信がだいぶなくなりました。個人手配が難しいとなると、旅行会社のツアーが候補になってきます。皆既日食を見に行くツアーはいろいろとあるのですが、ちょっと簡単に手が出ないほどの高価なツアーが多いです。今回については、安全を最優先として、個人手配は諦めました。何社か比較検討した結果、比較的安価で過去実績が良さそうな国際航空旅行サービス社のツアーに申し込むことにしました。
余談ですが、子供を海外旅行に連れて行くとなると、直前に体調を崩すことが心配になります。幸い、わりと丈夫な子供ですが、コロナウイルス・インフルエンザ・ノロウイルスなど、いつ感染してもおかしくない厄介な病気はいくらでもあります。今回は高価なツアーなのでキャンセル料も高価になってしまいます。リスクが高いので、はじめて海外旅行のキャンセル保険に入ることにしました。結局使わなかったですが、心の余裕を買う意味はあったと思いました。
機材選定
望遠鏡
望遠鏡は BORG 107FL にしました。通常、10cm以上の口径の望遠鏡を海外に持って行くのは相当大変だと思うのですが、BORG 107FLは対物レンズをコンパクトに収納できるのでカメラバッグに詰め込むことができます。対物レンズを機内持ち込みにできるのは相当のメリットがあると思います。

BORG 107FL と組み合わせる補正レンズはどうするかちょっと悩みました。2017年の時は BORG 71FL と1.4倍エクステンダー(BORG 7215)を使って焦点距離560mmで撮影しました。BORG 107FLと7215を組み合わせると840mmになってしまい、皆既日食を撮影するにはやや長すぎる感じがしました。皆既日食時のコロナを捉えるには600mm前後がよいようなので、補正レンズはフラットナー(BORG 7108)を使うことにしました。これなら、焦点距離648mm、f/6.1になるのでちょうどよいと思いました。
カメラ
カメラは2017年の時と同じく、SONY α7S にしました。2015年に購入したちょっと古いカメラですが、手ぶれ補正がないので軽く、ダイナミックレンジも広いので、皆既日食の撮影には今でも向いていると思います。
難点があるとすれば、バッテリー容量が小さく、日食の始めから終わりまで撮影しようとすると途中でバッテリーの交換が必要になることでした。そこで、USBモバイルバッテリーを接続できるアダプターを導入しました。これなら大容量のモバイルバッテリーを接続できるので、バッテリー切れの心配がほぼなくなります。現状α7Sはほとんど天体写真でしか使っていないので、このアダプターを付けていても特に不自由はありません。

架台
2017年の時はポラリエを使ったのですが、BORG 107FL を使うとなるとカメラ込みで4kgくらいにはなってしまうのでちょっと荷が重くなります。(それでも口径10cm級の望遠鏡としては軽いですが)
そこで、Sky-WatcherのAZ-GTiを使うことにしました。これは赤道儀ではなく経緯台なのですが、皆既日食を撮影するなら特に問題ありません。耐荷重も5kgあるのでまずまず余裕があります。昼間なので自動導入にはあまり期待できませんが、追尾性能は赤道儀とそれほど変わらない精度だと思いました。

移動
今回の旅は移動がなかなか大変でした。片道で丸2日を費やし、現地に3泊滞在して帰るという弾丸ツアーだったので、日食を見るとき以外は基本のんびりしているしかないという贅沢な時間でした。小学生がこの移動に耐えられるか若干心配でしたが、わりと元気で助かりました。
前日
前日には撮影のリハーサルを行いました。海外とはいえ、それなりに使い慣れた機材ではあるので、問題なく扱うことができたと思います。

天気は曇りで、太陽の周りに22度ハロが出ていました。なんとか太陽が見えるくらいの薄雲ではあったのですが、なかなか不安になる天気でした。

当日
当日はみなさん朝から撮影機材を設置していました。ホテルの敷地に望遠鏡がずらっと並んで、まるで展示会のようでした。かなり重量のある、タカハシの望遠鏡と赤道儀を持ってきている方もたくさんおられました。私は比較的軽量の機材にしましたが、望遠鏡の口径だけは最大級だったかもです。

皆既日食中は天気予報のとおりずっと曇っていましたが、薄雲を通してずっと太陽が見えていたのでなんとか撮影には成功しました。曇りの天気予報の中でも観測できたのでかなりのラッキーだったのだろうと思います。

小学生の子供も皆既日食を上手に観察できました。比較的年配の方が多いツアーで、小学生は私の子供1人だけだったので、何かと親切にしてもらえてありがたかったです。

日没時にはだいぶ天気が回復して晴れ間が出ていました。この季節の天気の予測はほんとに難しかったようです。プロの手配力には感服しました。

というわけで、2017年に引き続き皆既日食の観測に成功し、二連勝となりました。皆既日食は一生のうちでもそれほど多く見られる機会がないので、元気なうちに見ておきたいと思いました。次に日本で見られるのは2035年なので、それまでは元気でいたいところです。
撮影プロセス
撮影プロセスは2017年のときとだいたい同じですが、ずっと薄雲が出ていたので露出を試行錯誤する必要がありました。2017年の時はBORG 71FL+1.4倍エクステンダーを使ってf/7.9の光学系でしたが、今回はBORG 107FL+1.08倍フラットナーでf/6.1の約1段分明るい光学系だったので、薄雲を考慮して概ね2017年の時と同じ露出時間にしました。
- 第1接触(欠け始め)~皆既1分前まで
- ISO100, シャッター速度1/200sに設定, 念のためブラケット撮影1EVx5枚に設定(1/800, 1/400, 1/200, 1/100, 1/50s で一度に撮影)
- レリーズタイマーで3分おきに自動撮影
- 雲が濃くなってモニターから見えづらくなったらISO200~400程度に変更
- 皆既1分前~第2接触(ダイヤモンドリング)
- 太陽フィルターを外す
- シャッター速度1/1000sに設定, ブラケット撮影1EVx5枚に設定(1/4000, 1/2000, 1/1000, 1/500, 1/250s で一度に撮影)
- レリーズで手動連写
- ほんとはここで2EVx5枚にするつもりでしたが、露出を試行錯誤しているうちに設定するのを忘れました。今回これが1ミスです。
- 皆既中1
- シャッター速度1/250sに設定, ブラケット撮影1EVx5枚に設定(1/1000, 1/500, 1/250, 1/125, 1/60s で一度に撮影)
- シャッター速度1/60sに設定, ブラケット撮影1EVx5枚に設定(1/250, 1/125, 1/60, 1/30, 1/15s で一度に撮影)
- シャッター速度1/8sに設定, ブラケット撮影1EVx5枚に設定(1/30, 1/15 1/8, 1/4, 1/2s で一度に撮影)
- レリーズで手動連写各5回くらい
- 薄雲越しで適正露出がよくわからなかったので適当に露出をずらして撮影しました。ここでも2EVにするのを忘れてますが、まずまずいろんな露出の素材を撮影できたのでよかったです。2017年の時は皆既の時間が2分ほどしかなく慌ただしかったですが、今回は4分以上あったのでだいぶ余裕があったように思います。
- 皆既中2~第3接触(ダイヤモンドリング)
- シャッター速度を1/60sに設定
- 皆既残り1分半ほどでカメラを動画撮影に切り替え
- ここからは肉眼&双眼鏡での観測を楽しみました
- 第3接触~第4接触(日食の終わり)
- 太陽フィルターを付ける
- 露出1/200sに設定
- レリーズタイマーで3分おきに自動撮影
おまけ
壁紙用の画像を作ってみました。よろしければ個人利用の範囲でどうぞお使いください。
 1920x1080
1920x1080
 2560x1440
2560x1440
ZWO AM5のウェイトシャフトをモノタロウで特注してみた
概要
ZWO AM5のウェイトシャフトをモノタロウで特注してみました。結果として純正品の約半額で作ることができたので、何かの役に立つかもしれないと思い共有します。
AM5とは?
AM5とはZWO社から2022年に発売された赤道儀です。波動歯車という方式を採用しており、従来のドイツ式赤道儀とはまったく形状が異なります。ドイツ式赤道儀では、バランスウェイトを使用して望遠鏡とバランスを取る必要がありましたが、このAM5は積載量13kgまでであればバランスウェイト不要です。
調査
先述の通り、AM5は積載量13kgまでであればバランスウェイト不要ですが、バランスウェイトを使用すれば最大20kgまで積載することができます。私の手持ちの機材は13kgどころか10kgもないのでウェイトは不要なのですが、将来役立つかもしれないのであってもいいかなと思いました。
ウェイトシャフトは純正品があるのですが、税別5455円と、なかなかいい値段です。天体望遠鏡の界隈では、ネジや棒や板が数千円~数万円することもあるのでそれほど法外な値段でもないような気はしますが、もうちょっとなんとかなるのではないかと思いました。
ウェイトシャフトの仕様を確認すると、オスネジの仕様はM12・ピッチ1.75mmで、シャフトの外径は20mmであることがわかりました。モノタロウで調べてみると、このサイズの金物を特注できることがわかり、レビューを見ると赤道儀のウェイトシャフトとして使っている人もいるのでいけそうな気がしました。
発注
純正品にサイズが近く、半額くらいの値段になるように、以下のようなパラメータで発注することにしました。
| 項目 | 値 |
|---|---|
| 軸経(D) | 20mm |
| 長さ(L) | 200mm |
| P | 12mm |
| G | 17mm |
| V | 12mm |
| N | 12mm |
こちらのリンクで同じパラメータで作成することができます。2022/9/5の時点で税別2873円でした。
こちらのサービスはかなり素晴らしいのですが、1つ惜しいところがあり、オスネジの根元5mmのところにネジを切ることができません。これだと、オスネジをねじ込んでもちょっと浮いてしまいます。ネジを切らない部分を細くする加工(ヌスミ加工というそうです)ができると完璧なのですが、今のところ解決方法がないので、スペーサーがほしくなりました。内径12mm、外径20mmのものがあればちょうどよかったのですが、見つからなかったので内径12mm・外径15mmと、内径16mm・外径21mmの2個のスペーサーを組み合わせることにしました。税抜189円+229円=418円 なので許容範囲かなと思います。私は後から別で注文してしまったので送料が別にかかってしまいましたが、3500円で送料無料になるのでいっしょにまとめればよかったと思います。
納品
注文から2週間ほどで納品されました。
丁寧な梱包で届きました。

型番はこんな感じ。型番で仕様がわかるようになっているようです。

オスネジ側。根元の5mmのところにネジが切られていないところがあります。

メスネジ側。

AM5にそのまま取り付けると、ちょっと浮いてしまいます。

スペーサーを取り付けたところ。両面テープで固定すれば十分かなと思います。

スペーサーを取り付ければぴったりです。

反対側は、元々付属していたM12ネジがぴったり取り付けられます。

純正品と見間違うようなぴったり感です。

外径20mmなので、ビクセンGP互換のバランスウェイトなどを取り付けることができます。13kg以上のものを搭載する予定は当面ないので不要なのですが、つけてても害はないと思います。特に、経緯台モードで使うときは若干精神衛生上いいかもしれません。

こんな感じのアクセサリを付けることもできます。

まとめ
モノタロウで特注したシャフトは十分使えそうなことがわかりました。当面使うことはなさそうですが、純正品より安価に作れてとりあえず満足しました。赤道儀用のシャフトをこんなに簡単に特注できるとわかったのは収穫でした。
今回は片側オスネジ、片側メスネジのものを作成しましたが、両側メスネジで、片方にM12の全ネジをねじ込むようにするのもありかもしれないです。強度的には落ちるかもしれないですが。

")



房総半島最南端で天の川を撮影しました
コロナ禍で帰省もままならないので、家族を連れて県内に小旅行してきました。昼間は運転で、夜は天体撮影なのでなかなか肉体に堪えましたが、どちらも幸せなのでよしとしておきます。
撮影スポットは、ここ数年、年に1回は行っている房総半島最南端の野島崎にしました。ここは野島崎灯台があるのでだいぶ明るいですが、肉眼で天の川が見えてアクセスしやすいので私は気に入っています。

今回の成果はこれです。今年は春に天の川を見る機会がなかったですが、8月になって撮影できてよかったです。8月になると22時くらいには天の川が垂直になってかなりの見応えがあります。縦構図がぴったりでした。撮影データは以下のような感じです。
Samyang 24mm f/1.8 FE SONY α7S Kenko プロソフトンクリア Kenko スカイメモSで追尾 f/1.8, ISO3200, 30s x8枚スタック ステライメージ9でトーンカーブ調整 PhotoShopで背景合成 DenoiseAIでノイズ除去
今回は新機材を2つ使用しました。1つめは Samyang 24mm f/1.8 です。これは今年発売されたばかりの新しいレンズで、星景用に最適との触れ込みなので買ってみました。24mmという画角は、広角ながら天の川の中心部を大きく写すことができて、とても使いやすいと思いました。解放からかなりの解像度で、四隅に若干のコマ収差は見られるものの、ウェブ上で掲載する程度なら十分すぎると思いました。また、f/1.8の明るさは強力で、ISO3200・30秒の露出で十分に天の川を写すことができました。α7SならISO3200程度でもノイズは少ないのでとても相性が良さそうです。
もう1つの機材はKenkoプロソフトンクリアです。これは、星景写真によく使われるプロソフトンAフィルタより控えめなソフトフィルターで、こちらも去年発売された新しめの製品です。テストもせずいきなり使ってみましたが、明るい星のにじみ具合と天の川のつぶつぶ感がちょうどよく、プロソフトンAより好みでした。Samyang 24mmとプロソフトンクリアはとても使い勝手がよいことがわかったので、今後も天の川撮影の主力として使っていこうと思います。

 58mm ソフト効果用 001899")


CentOS 8 を Oracle Linux 8 に切り替える
概要
CentOS 8 を Oracle Linux 8 に切り替える方法について記載します。
背景
CentOS 8 の開発が終了し、CentOS Stream に統一されるとの発表がありました。CentOS Stream はRHELのプレリリース版のような位置づけで、特定のバージョンはなくローリングリリース方式となります。RHELの代わりに使えるケースもあると思いますが、特定のRHELのバージョンと合わせた環境がほしいような場合は要件に合わないこともあると思います。
Oracle Linux とは?
Oracle Linux は、Oracleによって開発されている RHEL Clone のLinuxディストリビューションで、10年以上の歴史があり、今も開発が続いています。
Oracle Databaseを代表とする血も涙もないライセンスのOracle製品とは異なり、Oracle Linuxは以下のようなかなり柔軟なライセンス体系となっています。
- 無料で使用できる。本番環境でも使用できる。(RHELは開発版は無償だが本番では使えない)
- サポートが必要なら必要な分だけ購入できる。(RHELは全部購入しないといけない)
- RHELやCentOSからも移行してもサポートを受けられる。
- Ksplice などの Oracle Linux 独自の機能もある。(要Premier Support)
かつてはずいぶん叩かれましたが、当時から今まで柔軟なライセンス体系のまま開発が継続されていますので、CentOSが無くなるなら現実的な移行先として有力なのではないかと思います。
CentOS → Oracle Linux の移行手順
Oracle LinuxはRHELおよびCentOSからの移行方法を公開しています。CentOS 6 or 7 からの移行方法はこちらに公開されていますが、CentOS 8 はやり方が違うようです。
(2020/12/16追記) 移行ツールがCentOS8にも対応しました。このページの内容はさっそく不要になりました。
CentOS 8 から Oracle Linux 8 への移行方法はサポートが必要なところにドキュメントがあるようです。(公開した方がいいと思うなー)
サポートが必要な情報を使うのは微妙なので、こちらで言及されていた方法でやってみようと思います。やってる内容はほとんど変わらないと思いますが。
移行してみるテスト
VirtualBoxにCentOS 8 をインストールします。
起動時はもちろん CentOSです。
Oracle Linuxのリポジトリから必要なRPMをダウンロードします。
$ repobase=http://yum.oracle.com/repo/OracleLinux/OL8/baseos/latest/x86_64/getPackage
$ wget \
${repobase}/redhat-release-8.3-1.0.0.1.el8.x86_64.rpm \
${repobase}/oraclelinux-release-8.3-1.0.4.el8.x86_64.rpm \
${repobase}/oraclelinux-release-el8-1.0-9.el8.x86_64.rpm
そのままだと依存関係でRPMが入らないので centos-linux-release を削除します。
# rpm -e --nodeps centos-linux-release
Oracle Linuxのリポジトリ関連のRPMをインストールします。
# rpm -ivh *.rpm
ociregionファイルを作っておきます。これはOCI(Oracle Cloud)ではリージョンに応じてリポジトリサーバを変えるための仕組みのようです。
# :> /etc/dnf/vars/ociregion
# dnf remove centos-linux-repos
これで、DNFのリポジトリはOracle Linuxのものになります。
# dnf repolist repo id repo name ol8_UEKR6 Latest Unbreakable Enterprise Kernel Release 6 for Oracle Linux 8 (x86_64) ol8_appstream Oracle Linux 8 Application Stream (x86_64) ol8_baseos_latest Oracle Linux 8 BaseOS Latest (x86_64)
パッケージをOracle Linuxのものに入れ替えます。CentOSとOracle Linuxのパッケージが混ざってもよければやらなくてもよいです。
# dnf --refresh distro-sync ... パッケージが入れ替わります
Oracle Linux 独自の Kernel(Unbreakable Enterprise Kernel)を使うこともできます。
# dnf install kernel-uek
EFI bootの場合は再起動する前に grub.cfg を作り直す手順も必要です。
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
ファイルがあることを確認します。
# ls -l /etc/grub2-efi.cfg lrwxrwxrwx. 1 root root 31 Nov 5 14:56 /etc/grub2-efi.cfg -> ../boot/efi/EFI/redhat/grub.cfg # ls -l /boot/efi/EFI/redhat/grub.cfg -rwx------. 1 root root 6544 Dec 11 04:51 /boot/efi/EFI/redhat/grub.cfg
再起動します。
# reboot
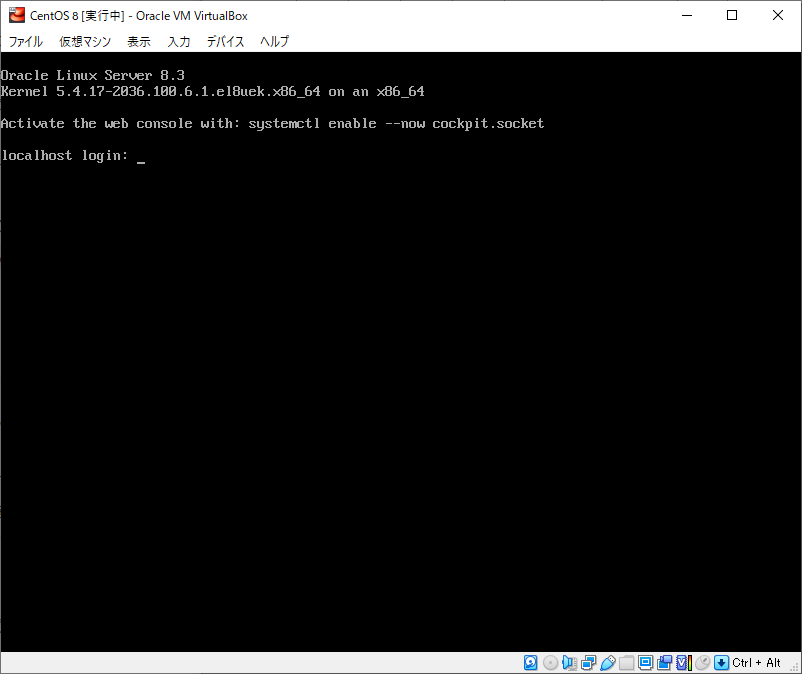
UEKで動作していることがわかります。
# uname -r 5.4.17-2036.100.6.1.el8uek.x86_64
/etc/oracle-release があります。
# cat /etc/oracle-release Oracle Linux Server release 8.3
Oracle Linuxでは、/etc/redhat-release には Red Hat と書かれてます。
# cat /etc/redhat-release Red Hat Enterprise Linux release 8.3 (Ootpa)
AWSソリューションアーキテクトアソシエイト(SAA-C02)受験体験記
概要
AWSソリューションアーキテクトアソシエイトの試験に合格しました。勉強期間は4週間ほどでした。幸い1回目の試験で合格することができました。勉強方法や試験の流れをメモしておきたいと思います。
モチベーション
勉強期間は少し特殊な状況でした。2020/10に第2子が生まれたのをきっかけに、会社の制度(妻出産休暇)を利用して4週間の休暇をいただきました。この1ヶ月はほぼ専業主夫状態で、家事全般と上の子(5歳)の世話をしてました。休暇といってもそんな感じなので、まとまった時間を取るのは難しいと思っていましたが、平日は上の子が保育園に行っている間に隙間時間があるかなと思ったので、何か資格でも取ろうかなと思っていました。
私はインフラエンジニア歴は長い部類ですが、クラウドの体系的な勉強はしたことがなかったので、AWSの勉強をしてみようと思いました。体系的に勉強するなら資格の勉強をするのがよいと思ったので、AWSの資格を取得してみようと思いました。AWSソリューションアーキテクトアソシエイトは、AWSの資格の中では中級程度に位置づけられる資格で、AWSのサービスを比較的幅広く理解している必要があります。今は業務上で開発や構築を本格的に行う機会は少ないですが、クラウドについて理解している必要はあるので、私に合っているかなと思いました。
勉強方法
勉強に用いた教材を紹介します。
私は主にこの教材で勉強しました。定価は12000円ですが、私が購入したときは1800円くらいでした。Udemyは毎月のように9割引とかのセールをやっているので、セールのタイミングで購入するのがいいと思います。最安だと1200円くらいになります。(定価っていったい...)
このコースでは、ハンズオン形式で実際のAWSのサービスに触れながら学習を進めることができます。今回は、試験に合格することよりも、AWSの様々なサービスに体系的に触れることが目的だったので、ハンズオン形式で勉強できるのがよかったです。AWSをあまり使ったことがなくても、インフラの知識がある程度あれば、タイトルのとおりこれだけで合格することは十分に可能だと思います。
AWSでは頻繁なサービスの変更がありますが、AWSのサービス変更に追随して、こちらのコースの教材も頻繁にアップデートされているようです。変更があった部分は都度説明が追加されていて親切だと思いました。画面が現行のサービスと多少異なる部分もありますが、AWSを使うならその程度は気にしない方がよいということだと思います。
AWSでは高額のサービスも簡単に使えてしまうので、気をつけないと後で高額の請求に驚くということになることがあります。勉強代とはいえ何万円もかかってしまうのはつらいですが、ある程度経験がないと勘所がわかりにくいと思います。このコースでは、月額だと何万円にもなる高額なサービスも使うことがありますが、高額なサービスは使用後すぐに削除するようにアドバイスしてもらえるので、AWSのコストは最小限で済みます。会社等でAWSを使える場合もあると思いますが、このコースではルートアカウントを使ったりするので、できれば自分でアカウントを作って、自分のクレジットカードでコストを気にしながら使った方がよく身につくんじゃないかと思います。結果的に、コース開始から終了まで約3週間使いましたが、AWSのコストは2.09米ドルでした。コーヒー1杯分くらいなので、このくらいなら安心して使えるのではないかと思います。
コストの内訳は以下のようになりました。
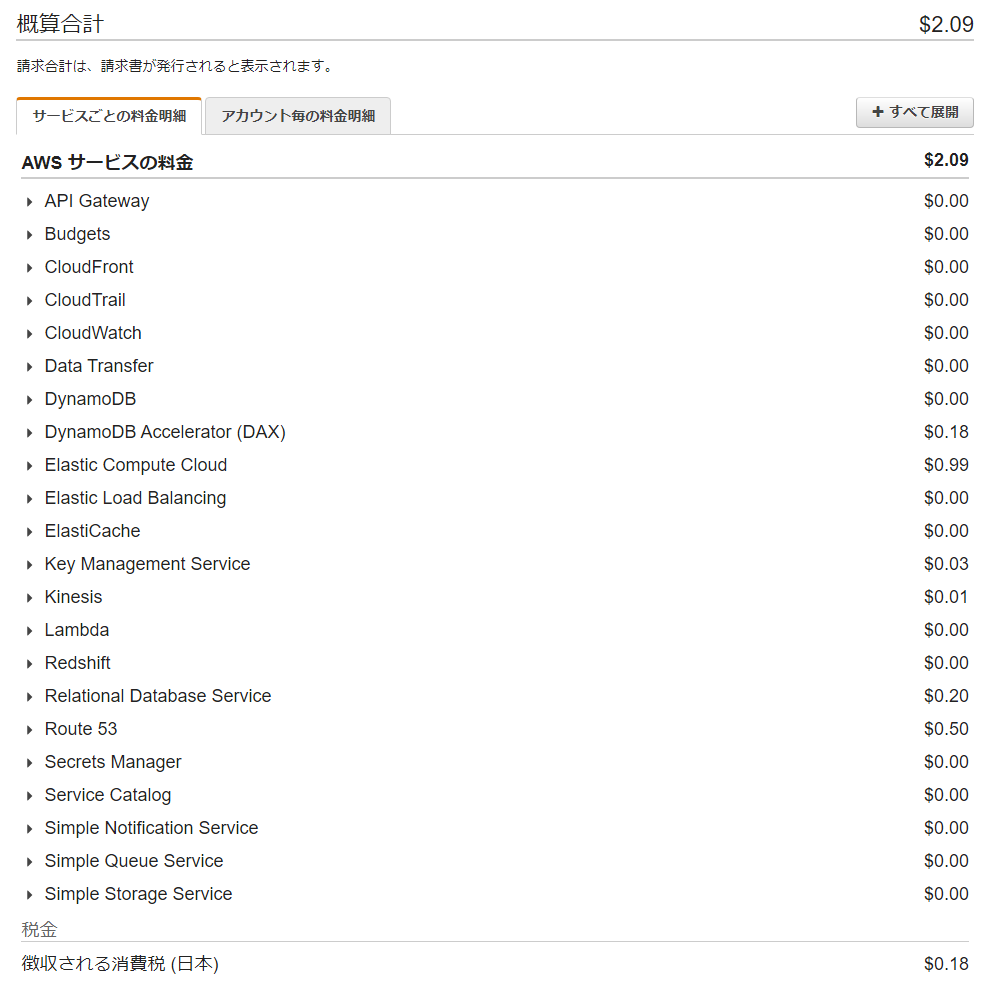
EC2が多いですが、EC2自体ではなくNATゲートウェイのコストが高めでした。EC2自体は無料枠で済んでいました。Elastic IPも少し課金されてますが、デタッチして放置してしまったことがあったので課金されてしまいました。デタッチしてすぐに解放すればもう少しコストを抑えられると思います。数十円なので誤差みたいなもんですが。

上記のハンズオンにも2回分の模擬試験が付いていますが、さらに6回分の模擬試験を収録した問題集です。こちらも割引があるときに1200円くらいで購入しました。難易度はやや高めなので、これで7割前後得点できていれば本番でも合格できる可能性が高いと思います。
こちらは試験用の教材ではありませんが、AWSソリューションアーキテクトの原典とも言える文書です。技術的なことだけでなく、組織やビジネスのあり方についても書かれていて、AWSの利用者に限らず役に立つと思うので、目を通すといいと思いました。
申し込み~試験
AWSの試験はベンダ系のIT資格でおなじみのピアソンで受験することができます。ウェブから都合のよい日を自分で選んで予約することになります。AWSの試験は、今ではオンラインでも受験することができるようになっていますが、周りに何もない部屋を用意しないといけないなど、私の自宅ではちょっと難しく、東京駅近くの試験センターに行って受験しました。
試験時間は140分です。140分で65問なので、まあまあ余裕があります。70分ほどで全問に解答し、自信がない問題にはマークを付けました。全問回答後、20分ほどでマークした問題を見直し、さらに20分ほどで全問を見直しました。12問ほど自信がない問題がありましたが、8割程度は得点できているだろうと判断し、30分ほど残して試験終了にしました。試験が終わると画面上で合否を確認することができます。無事に合格と表示されていたのでひとまず安心しました。
試験の言語は日本語で受験しましたが、画面上で英語も確認することができます。外資系ベンダの試験としてはそれほど変な日本語ではなかったかなと思いますが、ところどころサービス名や機能名の訳が実際のサービスと異なっているところがありました。日本語に違和感があったら英語を見てみた方がよいと思います。実際にAWSを使うなら英語のドキュメントを読むこともあると思うので、あまり細かいことは気にしない方がいいということだと思います。
合格後の対応
合格の翌日、正式な合格通知がメールで送られてきました。スコアは1000点中775点でした。8割くらいかなと思ったので想定の範囲内ですが、あまり余裕はなかったみたいです。合格するとこんな感じのロゴがもらえます。

試験に合格すると、模擬試験の無料での受講や、次回の試験の割引などの特典があるので、他の資格の取得を狙ってみてもいいかもしれません。試験に合格はしたものの、AWSのサービス一覧を見ると全く知らないサービスが山のようにあって正直なんもわかりません。AWSサービス多過ぎです。継続的な学習が必要かなと思います。
BORG 107FL + 笠井トレーディングV-POWER接眼部のセットアップ
概要
BORG 107FL と、笠井トレーディングV-POWER接眼部を組み合わせてみたメモです。BORGの各種補正レンズと組み合わせても無限遠が出る組み合わせになっています。
背景
2019年の消費税増税前に駆け込みでBORG 107FLとBU-1のセットを購入していました。シンプルでとてもいい組み合わせのように思ったのですが、BU-1のヘリコイドはアソビがやや大きくピントを合わせづらいと感じたのと、台座が1点支持なので107FLの対物レンズを支えるにはやや心許ないという不満点が出てきました。

天体写真を撮るには接眼部に微動装置がほしいと思ったので、サードパーティ製品も含めて探していたところ、笠井トレーディングのV-POWER接眼部がよさそうかなと思いました。以前はBORGのOEMで発売されていたこともあったようですが、今はより安価になって笠井トレーディングから発売されています。
鏡筒パーツ

鏡筒は以下のようなパーツを組み合わせています。
V-POWER接眼部+オプション
- V-POWERII接眼部L + BORG互換アダプター
- ファインダー脚台座
BORGパーツ
- 80φL135mm鏡筒BK【7138】
- M77.6→M68.8AD【7801】
- M57回転装置DX【7352】
- マルチバンド80Φ【7085】 x2個
- マルチバンド用スペーサーL20【7020】 x2個
- ロングプレート200【3200】
- アリミゾ式ファインダー台座BK【0610】
V-POWER接眼部はBORG互換のアダプター付きの製品があるのでそちらを購入しました。BORGの延長筒はたくさん種類があって迷いますが、各種補正レンズを取り付けてもピントが出る長さとして135mmを選びました。また、ドロチューブ無しでV-POWER接眼部を接続するために M77.6→M68.8AD【7801】も購入しました(買うのを忘れて、後から購入しました)。M57回転装置DX【7352】は元々持っていました。ちょっといい値段しますが、デジカメを取り付ける場合はあった方が便利です。鏡筒バンドはBORG純正にしたのでなかなかいい値段しますが、サードパーティ製品ならもうちょっと安価にできると思います。ファインダー台座はファインダーとガイド鏡を取り付けるために2個付けましたがこれはお好みで。
重量
BORG 107FLの対物レンズは1772gでした。

鏡筒部分は1643gでした。

対物レンズと鏡筒部を合わせると約3.4kgになります。ここに補正レンズも加えるともうちょっと重くなりますが、口径10cm級のアポクロマート鏡筒としては相当に軽いです。さらに分解収納できるので、飛行機での遠征等を視野に入れると非常に有力な選択肢になると思います。
7872レデューサとの組み合わせ
7872レデューサと組み合わせると下の写真のあたりで無限遠が出ます。ドロチューブを24mmほど繰り出した位置でピントが出ているので、135mmより長い150mmの鏡筒でも無限遠が出そうですが、かなりギリギリになってしまいそうです。


7872レデューサは90FLと71FL用なので107FLとの組み合わせはサポートされていませんが、相性はかなり良好に見えます。以下の作例はm4/3のカメラで撮影したものですが、ノートリミングで四隅までシャープです。フルサイズだと四隅が少し流れるらしいです。
ところで、海外では107FL専用レデューサとのセット製品が販売されているのですが、日本では発売されておらず残念です。かなり高価ですがほしい人はいるんじゃないでしょうか。
7108フラットナーとの組み合わせ
7108フラットナーと組み合わせるときは、M57/60延長筒M【7603】を使うとちょうど良いようです。下の写真のあたりで無限遠が出ます。

7215テレコンバータとの組み合わせ
7215テレコンバータと組み合わせるときも、M57/60延長筒M【7603】を使うとちょうど良いようです。下の写真のあたりで無限遠が出ます。

直焦点
あまり使うことはないと思いますが、補正レンズを使わない直焦点でも無限遠が出ます。バックフォーカスは十分あるので、天頂プリズムを取り付けて眼視もできます。


- メディア: エレクトロニクス

- メディア: エレクトロニクス

- メディア: エレクトロニクス

- メディア: エレクトロニクス